Big Data - Tập 1. Giới thiệu tổng quan Hadoop
Big Data, Apache Hadoop, Data Engineer ·1. MỞ ĐẦU
Apache Hadoop là một nền tảng phần mềm dựa trên Java, mã nguồn mở. Nền tảng này cho phép phát triển các ứng dụng phân tán (distributed processing) để lưu trữ và quản lý các tập dữ liệu lớn. Thay vì sử dụng một máy tính lớn để lưu trữ và xử lý dữ liệu, Hadoop cho phép tạo nhóm nhiều máy tính để phân tích các bộ dữ liệu lớn đồng thời một cách nhanh chóng hơn.
Ẩn sâu trong đó chính là mô hình MapReduce, mô hình mà ứng dụng sẽ được chia nhỏ ra thành nhiều phân đoạn khác nhau được chạy song song trên nhiều node khác nhau. Chính vì thế, nó có thể lưu trữ và xử lý hiệu quả các bộ dữ liệu lớn có kích thước từ hàng gigabyte đến hàng petabyte dữ liệu.
Khung của nó dựa trên lập trình Java với một số mã gốc trong các tập lệnh C và shell, tuy nhiên vẫn hỗ trợ C++, Python, Perl bằng cơ chế streaming.

2. Thành phần
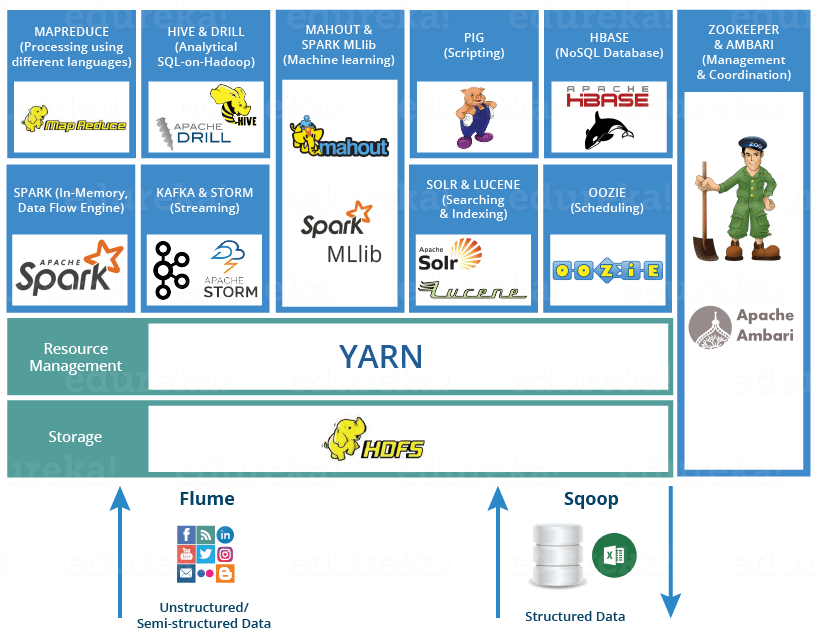
Hadoop có các thành phần chính:
-
HDFS (Hadoop Distributed File System - Hệ thống tệp phân tán Hadoop): Đây là thành phần lưu trữ của Hadoop, cho phép lưu trữ lượng lớn dữ liệu trên nhiều máy. Nó được thiết kế để hoạt động với phần cứng thông dụng, giúp tiết kiệm chi phí.
-
YARN (Yet Another Resource Negotiator): Đây là thành phần quản lý tài nguyên của Hadoop, quản lý việc phân bổ tài nguyên (chẳng hạn như CPU và bộ nhớ) để xử lý dữ liệu được lưu trữ trong HDFS.
-
MapReduce: là khung mô hình lập trình để xử lý và tính toán trên số lượng dữ liệu lớn trong môi trường phân tán. Nó hoạt động dựa trên 2 pha chính là Map và Reduce. Pha Map sẽ chia nhỏ dữ liệu thành các cặp key-value, sau đó pha Reduce sẽ nhóm các cặp key-value lại với nhau để tính toán kết quả cuối cùng.
-
Hadoop Common: Hadoop Common bao gồm các thư viện và tiện ích được sử dụng và chia sẻ bởi các mô-đun Hadoop khác.
Ngoài HDFS, YARN và MapReduce, toàn bộ hệ sinh thái nguồn mở Hadoop tiếp tục phát triển và bao gồm nhiều công cụ và ứng dụng để giúp thu thập, lưu trữ, xử lý, phân tích và quản lý dữ liệu lớn. Chúng bao gồm Apache Pig, Apache Hive, Apache HBase, Apache Spark, Presto và Apache Zeppelin.
Hadoop thường được sử dụng trong các bài toán dữ liệu lớn như data warehousing, business intelligence, và machine learning. Nó cũng được sử dụng để xử lý dữ liệu, phân tích dữ liệu và khai thác dữ liệu. Nó cho phép xử lý phân tán các tập dữ liệu lớn trên các cụm máy tính bằng mô hình lập trình đơn giản!
3. Lịch sử hình thành
Hadoop được phát hành chính thức vào năm 2005 bởi tập đoàn Apache Software. Apache Software là một trong những tổ chức phi lợi nhuận chuyên dụng trong việc sản xuất các phần mềm cũng như các mã nguồn mở từ đó hỗ trợ cho các nền tảng khác trên Internet.
Với hơn 18 năm phát triển nên Hadoop dần khẳng định được tầm quan trọng của chính mình trong quá trình lưu trữ cũng như xử lý cho các kho dữ liệu.
Thêm một thông tin ngoài lề khá thú vị cho bạn: Nếu bạn đang tự hỏi cái tên lạ tai Hadoop đến từ đâu, câu trả lời là Hadoop là tên của một chú voi đồ chơi thuộc về con trai của một trong số những người sáng lập ban đầu!
4. Hadoop làm việc như thế nào?
Nếu như bạn hay công ty của bạn không đủ điều kiện để xây dựng các máy chủ siêu mạnh thì chúng ta có thể kết hợp nhiều các máy tính thương mại lại để mang lại một cụm máy có khả năng xử lý một lượng dữ liệu lớn. Các máy trong cụm có thể đọc và xử lý dữ liệu song song để mang lại những hiệu quả cao. Bạn có thể chạy code trên một cụm các máy tính, quá trình này thông qua luồng sau đây:
- Dữ liệu được phân chia vào các thư mục và file. Mỗi file được chứa trong 1 blocks có kích thước cố định được xác định sẵn ( mặc định là 128MB)
- Các tệp này Yarn được phân phối trên các nút, cụm khác nhau
- HDFS nằm ở trên cùng của hệ thống file cục bộ, giám sát quá trình
- Các block được lưu các bản sao để đề phòng quá trình lỗi xảy ra trên phần cứng
- Kiểm tra mã được thực hiện thành công chưa
- Thực hiện bước Sort diễn ra giữa Map và Reduce
- Gửi data tới các máy nhất định để thực hiện các bước tiếp theo
- Viết log cho mỗi công việc hoàn thành
5. Các ưu điểm của Hadoop là gì?
Dưới đây là một số ưu điểm nổi bật của Hadoop:
- Hadoop có khả năng thêm nhiều node mới, xóa node và thay đổi được các cấu hình của chúng một cách dễ dàng.
- Hadoop không yêu cầu phần cứng của các máy trong cụm, bất cứ máy tính nào cũng có thể là 1 phần của cụm Hadoop. Hadoop sẽ phân công công việc hợp lý cho mỗi máy phù hợp với khả năng của mỗi máy. Vì vậy, các doanh nghiệp không cần phải đầu tư quá nhiều vào phần cứng. Nhờ vậy có thể tiết kiệm chi phí đầu tư.
- Hadoop có khả năng xử lý hầu hết những kho dữ liệu có cấu trúc hoặc không có cấu trúc.
- Hadoop cung cấp hệ thống có khả năng chịu lỗi và tính sẵn có cao. Thay vào đó thư viện Hadoop đã được thiết kế để xử lý lỗi từ tầng ứng dụng. Cụ thể, trong quá trình hoạt động, nếu một node trên hệ thống bị lỗi thì nền tảng của Hadoop sẽ tự động di chuyển sang dạng node dự phòng khác. Nhờ đó mà hệ thống có thể hoạt động xuyên suốt, ổn định hơn.
- Một lợi thế lớn khác của Hadoop là ngoài là mã nguồn mở, nó tương thích rất nhiều cấu hình và platform khác nhau vì nó dựa trên Java
6. Tổng kết
Hiện nay, nhu cầu lưu trữ dữ liệu của các doanh nghiệp ngày càng cao. Chính vì vậy, nguồn nhân lực thành thạo nền tảng này cũng đang là nhu cầu tuyển dụng mà rất nhiều công ty hướng đến. Nếu như bạn đam mê với nền tảng này thì đừng quên thử sức nhé. Chúc bạn sớm thành công!
Hi vọng với những kiến thức hữu ích ở phía trên thì bạn đọc đã hiểu rõ hơn Hadoop là gì? Các bài tiếp theo, mình sẽ đi sâu hơn vào từng thành phần của cụm Hadoop này cũng như cài đặt và triển khai một vài ví dụ nhé.
4. Tài liệu tham khảo
- https://cloud.google.com/learn/what-is-hadoop
- https://www.geeksforgeeks.org/hadoop-an-introduction/
- https://demanejar.github.io/posts/hadoop-introduction/