[Paper Explain][End-to-End Dense Video Captioning with Parallel Decoding] PDVC - Hướng tiếp cận end-to-end với giải mã song song cho bài toán Dense Video Captioning
AI, Computer Vision, Deep Learning, Video Understanding ·Xin chào các bạn. Chắc hẳn mọi người cũng đã từng nghe qua đến cái tên Video Understanding với rất nhiều các tác vụ con kèm theo đó là khá model nổi tiếng như:
- Action Recognition - Video Classification: TSN, TSM, I3D, SlowOnly, SLowFast, C3D, X3D, Timesformer, …
- Action Detection: BMN, SSN, ACRN, …
- Video Object Tracking: PraNet, LADCF, …
- Video Captioning & Dense Video Captioning: UniVL, COOT, VideoBERT + S3D, MDVC, BMT, PDVC, …
- ….
Ngoài ra, vấn đề End-to-End cũng đang được quan tâm rất nhiều và đang trở thành một xu hướng trong việc áp dụng, thiết kế mô hình. Có thể kể đến, Deformable DETR được áp dụng trong Object Detection, …
Trong bài này chúng ta sẽ cùng nhau tìm hiểu sơ qua về Dense Video Captioning cùng với đó là ý tưởng, kiến trúc, kĩ thuật trong PDVC - một mô hình hiện đang Top 1 trên tập data YouCook2 và Top 4 trên tập ActivityNet Captions để xem chúng áp dụng gì mà có thể ngồi cao như vậy? OK chúng ta sẽ bắt đầu ngay thôi 😁😁😁
Thuật ngữ được sử dụng:
- Single-sentence captioning: tạo phụ đề cho video chỉ với một câu văn
- Events: Một video dài sẽ được chia thành rất nhiều sự kiện. Mỗi sự kiện sẽ khái quát chính nội dung của một đoạn video nhỏ (mình viết như này không biết mọi người hiểu không nữa 🥶🥶 )
- Localizing: vị trí của một event (thứ tự, thời gian bắt đầu, thời gian kết thúc)
- Captioning: đoạn văn mô tả cho một event.
1. Video Captioning và các vấn đề gặp phải
Là một nhánh mới nổi của Video Understanding, Video Captioning ngày càng được chú ý trong thời gian gần đây. Bài toán này nhằm mục đích tạo ra một câu văn để mô tả một sự kiện chính (event) của một đoạn video ngắn. Tuy nhiên, vì video thực tế thường dài, không xác định thời lượng và bao gồm rất nhiều sự kiện (event) với nội dung cơ bản là không liên quan đến nhau, các phương pháp single-sentence captioning không thực sự tốt khi chỉ có ít thông tin.
Để giải quyết tình huống khó xử trên, Dense Video Captioning (DVC) được phát triển để tự động localizing và captioning cho nhiều event trong video, từ đó mô tả chi tiết nội dung hình ảnh và tạo mô tả mạch lạc và đầy đủ.
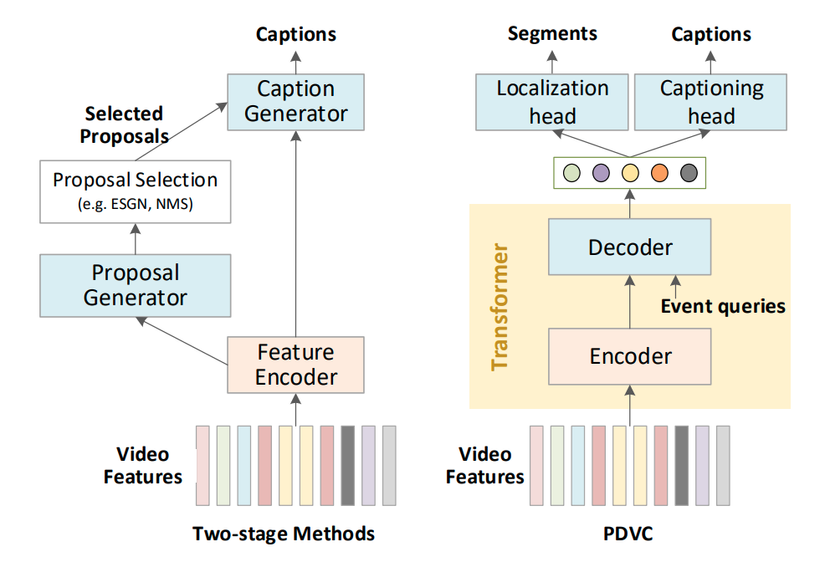
Hình 1: Two-stage pipeline và mô hình PDVC được đề xuất.
Dense Video Captioning có thể được chia thành hai nhiệm vụ phụ, gọi là event localization và event captioning.
Như được thể hiện trong Hình 1, các phương pháp trước đây thường giải quyết vấn đề này bằng Two-stage pipeline: localize-then-describe . Nó hoạt động như sau:
- Trước hết, extract ra các feature và dùng nó để dự đoán một tập hợp các đề xuất sự kiện - event proposal.
- Sau đó chọn lọc, lựa chọn lại các sự kiên - Event Selection bằng cách sử dụng ESGN, NMS .
- Cuối cùng, cho các Event Selected đã chọn kèm Feature Encoder đi qua Caption Generator, để sinh mô tả cho từng sự kiện.
Phương pháp trên là dễ tiếp cận, tuy nhiên nó gặp một số vấn đề sau:
- Coi Captioning là nhiệm vụ cuối cùng, việc thực hiện một trình tự như vậy phụ thuộc rất nhiều vào chất lượng của các event proposal đã tạo, điều này hạn chế sự thúc đẩy lẫn nhau của hai nhiệm vụ phụ này.
- Hiệu suất của trình tạo sự kiện - proposal generation trong các phương pháp trước đây phụ thuộc vào careful anchor design (dựa vào các anchor để tạo) và lựa chọn sự kiện - proposal selection sau xử lý (sử dụng ESGN, NMS). Các thành phần được sử dụng cản trở phương pháp tiến tới end-to-end.
Để giải quyết các vấn đề trên, tác giả đề xuất một mô hình end-to-end với Giải mã song song được gọi là PDVC.
- Như thể hiện trong Hình 1, thay vì sử dụng theo hướng Two-stage pipeline, tác giả đưa trực tiếp phần extract feature vào captioning head song song với localization head (cái tên Parallel Decoding cũng xuất phát từ đây). Bằng cách đó, PDVC nhằm mục đích khai thác trực tiếp sự liên kết giữa 2 tác vụ ở feature level.
- Đề xuất event counter để ước tính số lượng sự kiện trong video, giúp tăng đáng kể khả năng của generated captions bằng cách tránh ước tính số lượng sự kiện không có thực.
2. PDVC
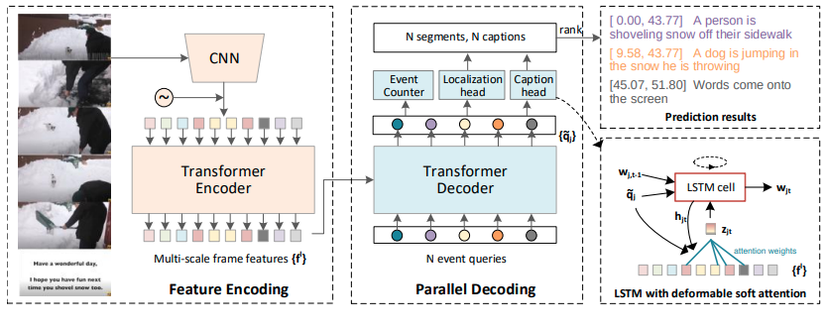
Hình 2: Tổng quan về phương pháp đề xuất - PDVC
2.1. Tổng quan mô hình
Từ hình số 2, ta có thể hình dung mô hình sẽ hoạt động như sau:
- Đầu tiên, chúng tôi sử dụng một pre-trained video feature extractor và một transformer encoder để có được chuỗi các frame-level features.
- Sau đó, transformer decoder và ba heads dự đoán (Event Counter, Localization head, Caption head) được đề xuất để dự đoán vị trí, mô tả và số lượng event có thể học được từ N event queries.
Những thứ bên lề khác:
- Tác giả cung cấp hai loại Caption heads, tương ứng dựa trên vanilla LSTM và deformable soft-attention enhanced LSTM (trong hình là sử dụng cái 2).
- Event Counter sẽ được dự đoán dự trên captioning score and localization score mà không cần sử dụng non-maximum suppression như các phương pháp trước đây.
- Kiến trúc Encoder-Decoder được sử dụng ở trên chính là mô hình Deformable transformer. Nó được sử dụng để nắm bắt các tương tác giữa inter-frame, giữa inter-event và event-frame bằng attention và tạo ra một tập hợp các event query features.
2.2. Deformable Transformer
Deformable Transformer là một kiến trúc Encoder-Decoder dựa trên multi-scale deformable attention (MS-DAtt) .
Vì nói phần này sẽ rất dài, nên có lẽ mình sẽ dẫn link để mọi người tìm hiểu sâu hơn về nó:
- Link paper: https://arxiv.org/pdf/2010.04159v4.pdf
- Link github: https://github.com/fundamentalvision/Deformable-DETR
2.3. Feature Encoding
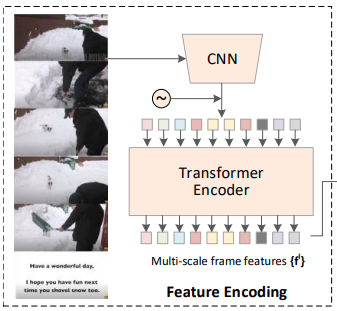
Hình 3: Feature Encoding
Các điểm chính trong phần này như sau:
- Để ghi lại Spatio-temporal features (đặc trưng về không - thời gian) trong một video, trước tiên, chúng tôi sử dụng mạng pre-trained action recognition (ví dụ: C3D , TSN, …) để trích xuất các frame-level features.
- Tiếp theo, re-scale feature map’s temporal thành một số cố định T.
- Sau đó, để sử dụng tốt hơn các features, tác giả thêm các lớp L temporal convolutional (stride = 2, kernel size = 3) để có được feature sequences trên nhiều độ phân giải, từ T đến T / 2L.
- Các multi-scale features với việc nhúng positional embedding được đưa vào deformable transformer encoder, trích xuất mối quan hệ frame-frame trên nhiều tỷ lệ.
2.3. Parallel Decoding
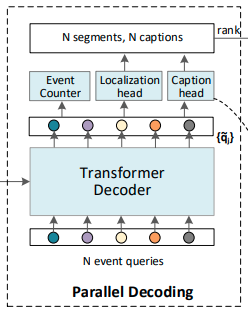
Hình 4: Parallel Decoding
Các điểm chính trong phần này như sau:
- Decoding network chứa deformable transformer decoder và ba đầu song song (captioning head để tạo phụ đề, localization head để dự đoán vị trí của các event với điểm tin cậy và event counter để dự đoán số lượng sự kiện phù hợp)
- N Event queries: Tác giả không để cập đến cái này trong paper. Nhưng theo ý hiểu của mình, cái này khá giống khái niệm Object queries mà trong paper về DETR đã giới thiệu. Về cơ bản, ta sẽ set N cho trước, nó sẽ tìm cách truy vấn, tìm những event features nào match nhất với nó hay chính xác là tìm event nào trên video match với từng thành phần của nó.
2.3.1. Localization head
Localization head thực hiện dự đoán box và binary classification cho mỗi event query.
- Dự đoán box nhằm mục đích dự đoán 2D relative offsets (center and length) của ground-truth segment và reference point.
- Binary classification nhằm mục đích tạo ra foreground confidence của mỗi event query.
Cả dự đoán box và binary classificationn đều được thực hiện bởi multi-layer perceptron. Sau đó, chúng ta thu được một tập hợp các bộ giá trị {$t_j^s$, $t_j^e$, $c_j^{loc}$} (j->N) để đại diện cho các event được phát hiện, trong đó $c_j^{loc}$ là localization confidence của truy vấn sự kiện $q_j$.
2.3.2. Captioning head
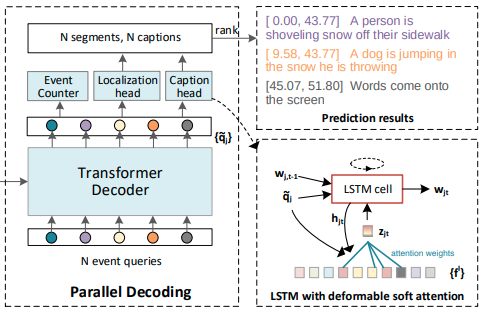
Hình 5: Parallel Decoding với Captioning head
Tác giả cung cấp hai captioning heads: lightweight one và standard one (một đầu nhẹ và một đầu chuẩn).
- Lightweight head: chỉ cần đưa vào $q_j$ một vanilla LSTM ở mỗi timestamp. Từ $w_{jt}$ được dự đoán bởi một lớp FC, theo sau là một hàm kích hoạt softmax trên hidden state $h_{jt}$ của LSTM.
Tuy nhiên, lightweight captioning head chỉ nhận được biểu diễn event-level $q_j$, thiếu sự tương tác giữa các tín hiệu ngôn ngữ và frame features. Để giảm bớt vấn đề này, tác giả đề xuất sử dụng deformable soft attention (DSA) để thực thi soft attention weights tập trung vào một khu vực nhỏ xung quanh các điểm tham chiếu - reference points.
Các bước thực hiện như sau:
- Đầu tiên ta có, $w_{j,t-1}$ là các từ dự đoán trước đó, $p_j$ là reference points, $q_j$ là event query và hidden state $h_{jt}$ của LSTM.
- Ta tạo ra K điểm lấy mẫu trên $f^l$ với điều kiện trên $q_j$ và hidden state $h_{jt}$.
- Sau đó, chúng tôi coi các điểm lấy mẫu K × L là key/value và [$h_{jt}$, $q_j$] là query trong deformable soft attention
- Vì các điểm lấy mẫu được phân bố xung quanh điểm tham chiếu $p_j$, các đặc trưng đầu ra $z_{jt}$ của DSA bị hạn chế tham gia trên một vùng tương đối nhỏ.
- LSTM lấy làm đầu vào là sự kết hợp của context features $z_{jt}$, event query $q_j$ và các từ trước đó $w_{j,t-1}$.
- Xác suất cho từ $w_{j,t}$ tiếp theo thu được bởi một layer FC với hàm softmax trên $h_{jt}$
- Sau cùng, chúng ta thu được một câu $S_j$ = { $w_{j1}$, …, $w_{jM_j}$}, trong đó $M_j$ là độ dài câu.
2.3.3. Event Counter
Ta thấy rằng, Số event thích hợp là một chỉ số cần thiết cho bài toán Dense Video Captioning:
- Nếu trong video có quá nhiều event, sẽ gây ra việc phụ đề bị trùng lặp và khả năng đọc kém.
- Tuy nhiên, nếu quá ít event được phát hiện có nghĩa là thông tin bị thiếu và mô tả video không đầy đủ.
Event Counter nhằm mục đích phát hiện số sự kiện của một video. Nó chứa một max-pooling layer và một lớp FC với hàm kích hoạt softmax:
- Trước tiên nén thông tin nổi bật nhất của event queries $q_j$ thành một vectơ đặc trưng toàn cục.
- Sau đó dự đoán một vectơ kích thước cố định $r_{len}$.
- Trong giai đoạn inference, số sự kiện dự đoán thu được bởi $N_{set}$ = argmax ($r_{len}$,).
- Kết quả cuối cùng thu được bằng cách chọn các sự kiện $N_{set}$ hàng đầu với boundaries chính xác và caption tốt từ N event queries. Độ tin cậy - confidence của mỗi event query được tính bằng:
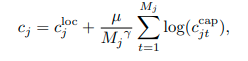
trong đó $c_{jt}^{cap}$ là xác suất của từ được tạo ra. Tác giả nhận thấy rằng confidence trung bình các từ không phải là một phép đo tốt ở cấp độ câu vì captioning head có xu hướng tạo ra confidence cao đối với các câu ngắn. Do đó, thêm hệ số điều chỉnh γ để điều chỉnh ảnh hưởng của độ dài câu. µ là hệ số cân bằng.
2.4. Loss Funtion
Trong quá trình training, PDVC tạo ra một tập hợp N event với các vị trí và chú thích của chúng. Chúng ta sẽ tìm cách so sánh từng event được dự đoán với từng ground truths.
Tổng loss ta cần tính, là tổng của từng thành phần: gIOU loss, classification loss, countering loss, and caption loss
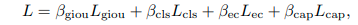
trong đó:
- $L_{giou}$ đại diện cho IOU tổng quát giữa các box được dự đoán - predicted temporal segments và box thực tế - ground-truth segments.
- $L_{cls}$ đại diện cho focal loss giữa predicted classification score và nhãn xác thực - groundtruth label.
- $L_{cap}$ là cross-entropy giữa xác suất từ được dự đoán và từ đúng được normalized bởi độ dài caption.
- $L_{ec}$ cũng là cross-entropy loss giữa predicted count distribution and the ground truth.
2 loss đầu là của Localization head, tiếp theo là Captioning head và cuối cùng là Event Counter.
2.5. Kết quả
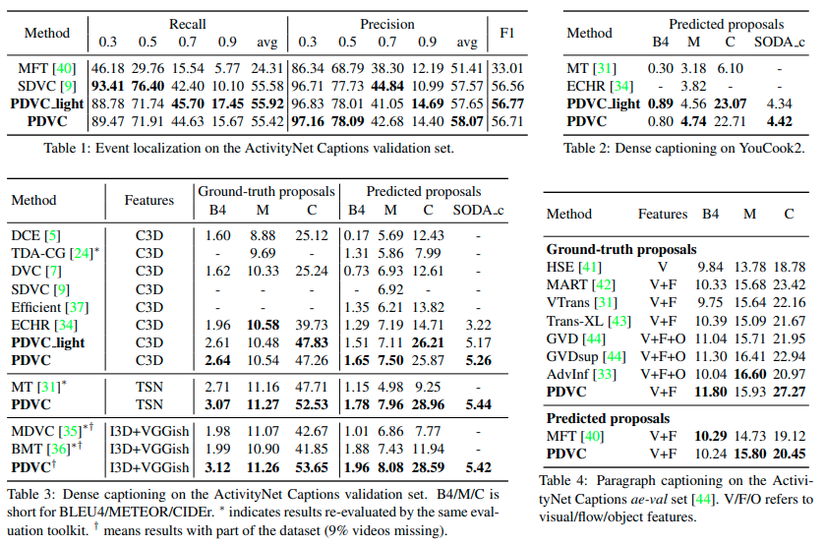
Hình 6: Kết quả thực nghiệm của tác giả khi thử nhiều phương pháp, và so sánh với các mô hình Video Captioning khác nhau.
3. Tổng kết
PDVC là một kiến trúc rất mới, đặc biệt nó thiết kế theo xu hướng end-to-end và vận dụng rất tốt việc predict song song 2 nhiệm vụ đó là: Localization và Captioning. Bằng việc áp dụng kiến trúc Deformable Transformer kèm thêm Event Counter, nó đã suất sắc nằm trong top các tác vụ về Dense Video Captioning hiện nay.
Bài viết chắc chắn sẽ còn nhiều thiếu sót, rất mong nhận được góp ý của mọi người để bài viết trở nên tốt hơn. Cảm ơn các bạn đã theo dõi và đọc bài của mình, nếu các bạn thấy bài viết hay thì có thể cho mình 1 upvote và 1 bookmark nha. See ya!